안녕하세요.
jimol입니다.
오늘은 니들만-브니쉬 알고리즘을 이용하여
유전자 염기서열을 정렬하는 프로그램을 만들어보려고 합니다.
그에 앞서 서열정렬(sequence alignment)과 니들만-브니쉬 알고리즘이 무엇인지 알아볼게요!

서열정렬(sequence alignment)이란?
유전자나 단백질의 서열을
다이내믹 프로그래밍 기반의 컴퓨터 스트링 정렬 알고리즘을 이용하여 배열하는 것입니다.
alignment를 직역하면 '맞추다, 정렬하다, 배열하다'인데, 그 의미를 단백질의 아미노산 서열, 유전자의 염기서열에 적용시켰다고 생각하면이해하기가 쉬울 것 같아요.
니들만-브니쉬 알고리즘(Needleman–Wunsch algorithm)은
생물정보학(bioinfo)에서
단백질 또는 뉴클레오타이드 서열을 정렬하는데
사용되는 대표적인 알고리즘입니다.
니들만-브니쉬 알고리즘을 자세히 알아보고
염기서열을 정렬해주는 프로그램을 만들어볼게요..
[니들만-브니쉬 알고리즘]

*gap:값이 비어있음.(-1), 오른쪽과 아래방향
*match: 맞음.(+1), mismatch: 안맞음: (+0), 오른쪽&아래 대각선 방향
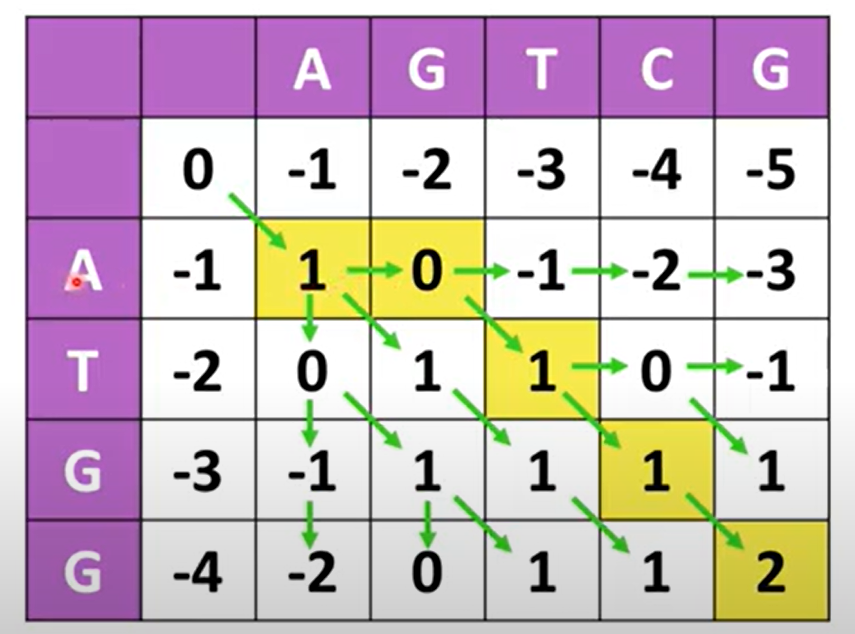
이해하기 쉽도록 2차원배열을 이용하여 표현할게요.
arr[0][0]은 사진을 참고하였을 때 0에 해당되는 칸입니다.
먼저 니들만-브니쉬 알고리즘은 score matrix라는 표를 만들어서 점수를 매깁니다.
점수를 매기는 방식은 다음과 같아요.
1. 비교하고자 하는 두 서열을 표의 열과 행에 앞에 하나의 빈칸을 두고 배치한다.
2. arr[0][j], arr[i][0]은 비어있는 칸과의 관계를 나타내므로 gap에 해당된다.
오른쪽, 왼쪽방향으로 gap은 -1의 값이므로 빈칸에 빈칸을 더하는 식으로 i와 j가 1씩 증가할 때 arr[0][j], arr[i][0]은-1씩 더해진다.
3. arr[1][1]같은 경우 대각선 방향으로(match or mismatch) A-A match이므로 +1, 0+1=1오른쪽 방향으로 gap이었던 arr[0][1]이 비어있어서 비어있는 것과의 비교니까 gap이므로 -1, -1-1=-2
아래쪽 방향으로 gap이었던 arr[1][0]이 비어있어서 비어있는 것과의 비교니까 gap이므로 -1, -1-1=-2
1,-2,-2 중 가장 큰 수를 선택하여 방향과 수를 기입해주면됩니다. arr[1][1]=1(대각선방향)
4. arr[2][1]같은 경우 대각선 방향으로 A-G mismatch이므로 +0, -1+0=-1오른쪽 방향으로 gap이니까 -1, 1-1=0아래쪽 방향으로 gap이니까 -1, -2-1=-3
-1,0,3 중 가장 큰 수인 0과 방향을 결정하여 기입해준다. arr[2][1]=0(오른쪽방향)
5. 이와같은 방식으로 score matrix를 모두 채웠으면 가장 끝칸 arr[5][4]에서 부터 거슬러 올라가 정렬을 해준다.
최종 alignment:
AGTCG
A-TGG
으로 1은 alignment가 되었다는 의미이고 0은 gap이라는 의미여서 -로 gap을 나타내줍니다.
니들만-브니쉬 알고리즘에 대해 알아보았으니 이제 코드를 짜볼게요!!
저는 c가 가장 편하기 때문에.. c를 사용하여 만들었습니다.

순서도를 그려봤습니다.
#include <stdio.h>
char seq1[100];
char seq2[100];
int com[4];
int ali[10];
int score[100][100];
int d[10][10];
int l1,l2,e,ol1,ol2;
int compare(int i, int j)//재귀함수
{
com[1]=score[i-1][j]-1;//GAP오른쪽-1
com[2]=score[i][j-1]-1;//GAP아래쪽-1
if(seq1[i]==seq2[j])//MATCH
{
com[3]=score[i-1][j-1]+1;//대각선 방향 +1
}
else if(seq1[i]!=seq2[j])//MISMATCH
{
com[3]=score[i-1][j-1];//대각선 방향 +0
}
com[4]=(((com[1] > com[2]) ? com[1] : com[2]) > com[3]) ? ((com[1] > com[2]) ? com[1] : com[2]): com[3];//가장 큰 수 찾기
if(com[4]==com[1])//가장 큰 수가 오른쪽
{
d[i][j]=1;
}
else if(com[4]==com[2])//가장 큰 수가 아래쪽
{
d[i][j]=2;
}
else if(com[4]==com[3])//가장 큰 수가 대각선
{
d[i][j]=3;
}
return com[4];//가장 큰 수 보내기
}
int main()
{
printf("염기서열길이을 입력하세요. \n");
printf("l1: ");
scanf("%d",&l1); //1의 길이 입력받기
printf("l2: ");
scanf("%d",&l2);//2의 길이 입력받기
ol1=l1;
ol2=l2;
printf("염기서열을 입력하세요. \n");
printf("seq1: ");
for(int i=1; i<=l1+1; i++)
{
scanf("%c",&seq1[i]);//배열에 1의 서열 입력받기
}
printf("seq2: ");
for(int i=1; i<=l2+1; i++)
{
scanf("%c",&seq2[i]);//배열에 2의 서열 입력받기
}
score[0][0]=0;
for(int i=1; i<=l1; i++)
{
score[i][0]=score[i-1][0]-1;//첫번째 행 GAP 대입
}
for(int j=1; j<=l2; j++)
{
score[0][j]=score[0][j-1]-1;//첫번째 열 GAP 대입
}
for(int i=1; i<=l1; i++)
{
for(int j=1; j<=l2; j++)
{
score[i][j]=compare(i,j);//재귀함수 compare로 이동하여 가장 큰수 받기
}
}
ali[0]=score[l1][l2];//가장 끝에 있는 score 저장
for(int k=0; k<=10; k++)
{
if(l1==0 || l2==0)//거슬러 올라갔을 때 행열 중 0되면 반복문 빠져나오기
{
e=k;//그때의 k값 저장해두기
break;
}
if(d[l1][l2]==1)//왼쪽에서 왔을 때
{
ali[k+1]=score[l1-1][l2];//score값 저장
l1--;
}
else if(d[l1][l2]==2)//위에서 왔을 때
{
ali[k+1]=score[l1][l2-1];//score값 저장
l2--;
}
else if(d[l1][l2]==3)//대각선 왼쪽 위에서 왔을 때
{
ali[k+1]=score[l1-1][l2-1];//score값 저장
l1--;
l2--;
}
}
printf("\n");
printf("SCORE MATRIX:\n");//table 출력
for(int i=0; i<=ol1; i++)
{
for(int j=0; j<=ol2; j++)
{
printf("%d ",score[i][j]);
}
printf("\n");
}
printf("\n");
for(int i=e; i>=0; i--)
{
printf("%d ",ali[i]);//정렬 score 출력하기(순서 거꾸로 출력)
}
return 0;
}
코드와 출력결과는 다음과 같아요.
score matiix을 전부 출력하여 table처럼 한눈에 파악할 수 있게 했고
마지막엔 alignment score를 구해서 출력해주었어요!
이번 프로그램을 코딩하면서
2차원배열과 1차원배열을 섞어쓰면서 원하는 값을 불러오는 과정에서
배열을 어떻게 저장해뒀는지 헷갈리더군요.
따로 종이에 배열과 변수의 의미를 기록해두면서
코드를 만들고 디버깅하는데에 어려움을 덜 수 있었습니다.ㅎㅎ
다만 score를 계산하는 과정을 구현하는 과정에서 오류가 발생하였어요.
코드를 처음 만들 때,
니들만-브니쉬 알고리즘의 과정 중
3가지의 방향의 값을 비교하여 가장 큰 값을 저장한다는 과정을
모든 배열에 적용시키는 코드를 main에 넣으려고 했었습니다.
그렇게 하다보니
이중 for문 안에 이중 중복문이 들어가 코드가 너무너무너무 복잡해지는
대참사가 발생하였습니다...
그래서 저는 비교하는 과정을
main에서 분리시켜 재귀함수를 만들어 구현하였습니다 .
재귀함수를 쓰니까 main에서 알고리즘을 한눈에 파악하기 편하고
무엇보다 반복적으로 사용해야하는 코드를 재귀함수로 설정해두어
코드의 복잡성도 낮아졌다고 볼 수 있을 것 같아요.
재귀함수를 사용하기 위해서
전역변수를 선언하여 main에서 compare(재귀함수)에 변수를 입력해줄 때와
return 받을 때 제 값을 주고받을 수 있도록 하였습니다.
순탄하게 흘러가는 듯 싶었지만...
코드를 출력해보니
matrix가 출력이 안되더라구요..
문제의 원인을 찾아보니 바로 전역변수로 설정해둔 변수에 저장된 값이 달라졌는데,
출력할 때 처음 입력받은 수를 사용하려고 하다가 발생한 문제였어요.
이 문제는 따로 다른 변수를 선언해서 저장해두고 불러오는 것으로 해결하여
정상적으로 출력되도록 하였습니다!!
이번 프로그램은 제가 정융탐을 하면서 만든 프로그램 중에
가장 어려운 개념을 다룬 것 같아서 만들고 나서 매우 보람찼습니다.
생각했던 것보다 코드를 만드는 과정에서 어려움을 겪진 않아서
다행이었지만, 정융탐 과제 중 가장 오래걸린 프로그램이었어요.
다음에는 정렬 score를 가지고 염기서열을 정렬하는 프로그램을 만들어서
이 프로그램과 함께 응용하면 좋을 것 같네요..
그럼 바이!
'정.융.탐' 카테고리의 다른 글
| [정.융.탐] 염기서열 콘솔 게임 만들기 (0) | 2023.07.03 |
|---|---|
| [정.융.탐] Michaelis-Menten 모델 프로세싱으로 구현하기 (0) | 2023.07.02 |
| [정.융.탐] Tm(melting temperature) 비교 프로그램 만들기 (1) | 2023.05.10 |
| [정.융.탐] 해파 속력 계산기 만들기 (0) | 2023.04.30 |
| [정.융.탐] 하디-바인베르크 법칙을 코딩으로 구현하기 (2) | 2023.03.09 |



